调试前准备
对于大部分的开源项目,一般都可以从其启动shell脚本中分析出来java启动类。我这里clone源码后以tag 3.9.1为主创建了一个分支,方便注释,调试。
在bin/zkServer.sh脚本中,其启动逻辑如下,如果是执行的./zkServer.sh start的话,最终执行的命令大概是
nohup java [一堆参数] org.apache.zookeeper.server.quorum.QuorumPeerMain [输出日志],ZOOMAIN变量可以往上溯源,四个出现的地方最终都是QuorumPeerMain类。因此QuorumPeerMain类就是zookeeper的启动类。
case $1 in
start)
echo -n "Starting zookeeper ... "
if [ -f "$ZOOPIDFILE" ]; then
if kill -0 `cat "$ZOOPIDFILE"` > /dev/null 2>&1; then
echo $command already running as process `cat "$ZOOPIDFILE"`.
exit 1
fi
fi
nohup "$JAVA" $ZOO_DATADIR_AUTOCREATE "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" \
"-Dzookeeper.log.file=${ZOO_LOG_FILE}" \
-XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError='kill -9 %p' \
# $ZOOMAIN= org.apache.zookeeper.server.quorum.QuorumPeerMain
-cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null &

知道启动类之后,就要进入debug模式进行调试,这里有两个点需要注意:
设置启动参数
由于shell脚本通过命令行模式执行的时候拼接了非常多的参数,虽然大部分参数都可以忽略,但是config参数确是必须的,即ZOOMAIN 后的 “ZOOCFG”。因此在通过idea等编辑器进行debug的时候,要设置program arguments为zk的配置文件(这里的zoo.cfg是复制的zoo_sample.cfg)

启动时报类找不到,编译失败
这是由于在pom文件中,有部分依赖的scope是provider类型,即zk项目本身不提供,由依赖方提供。我这里为了省事,将zookeeper-server的pom.xml里所有
<scope>provided</scope>都够注释掉了当涉及到客户端和服务端通信时,建议session过期时间设置的长一些,不然在debug的时候总是会session过期,连接关闭

但是由于有最大限制,因此建议临时注释掉最大限制的逻辑

源码分析
QuorumPeerMain
QuorumPeerMain类的逻辑相对简单,需要注意的是集群和单机两种模式走的是不同的逻辑。下面我会先分析单机模式熟悉结构后,再去看集群模式。
public static void main(String[] args) {
QuorumPeerMain main = new QuorumPeerMain();
try {
main.initializeAndRun(args);
}
protected void initializeAndRun(String[] args) throws ConfigException, IOException, AdminServerException {
//args[0]一般是zk的配置文件zoo.cfg,即这里将配置文件转换为javaBean
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
config.parse(args[0]);
}
// Start and schedule the the purge task
//通过定时执行PurgeTask来清楚data数据和datalog数据
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(
config.getDataDir(),
config.getDataLogDir(),
config.getSnapRetainCount(),
config.getPurgeInterval());
purgeMgr.start();
// 集群和单机两种方式
if (args.length == 1 && config.isDistributed()) {
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running in standalone mode");
// there is only server in the quorum -- run as standalone
//单机模式
ZooKeeperServerMain.main(args);
}
}
ZooKeeperServerMain

单机版的组件主要如上图所示。
AdminServer: zk通过jetty简单实现了一个后端admin,可通过http://localhost:8080/commands去进行一些操作。
MetricsProvider:用于记录、监控一些指标,本文不做分析
JvmPauseMonitor: 来源于hadoop的一个监控,有个线程一直死循环,当判断系统暂停时间大于一定指标,打印一条信息
JMX: java所提供的jmx
QuorumPeerConfig: 读取的是zoo.cfg,服务于zk集群模式
ServerConfig: 读取的也是zoo.cfg,但是仅限于zk单机模式,且主要服务于通信组件
启动入口
final ZooKeeperServer zkServer = new ZooKeeperServer(jvmPauseMonitor, txnLog, config.tickTime, config.minSessionTimeout, config.maxSessionTimeout, config.listenBacklog, null, config.initialConfig);
boolean needStartZKServer = true;
if (config.getClientPortAddress() != null) {
cnxnFactory = ServerCnxnFactory.createFactory();//默认是NIOServerCnxnFactory
cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), config.getClientPortListenBacklog(), false);
//启动入口
cnxnFactory.startup(zkServer);
// zkServer has been started. So we don't need to start it again in secureCnxnFactory.
needStartZKServer = false;
}
public void startup(ZooKeeperServer zks, boolean startServer) throws IOException, InterruptedException {
//启动socket相关的线程
start();
setZooKeeperServer(zks);
if (startServer) {
//启动zkDataBase
zks.startdata();
//启动其他组件(限流、processor、session、jmx等)
zks.startup();
}
}
通信流程

ServerCnxnFactory
public void start() {
stopped = false;
if (workerPool == null) {
workerPool = new WorkerService("NIOWorker", numWorkerThreads, false);
}
for (SelectorThread thread : selectorThreads) {
if (thread.getState() == Thread.State.NEW) {
thread.start();
}
}
// ensure thread is started once and only once
if (acceptThread.getState() == Thread.State.NEW) {
acceptThread.start();
}
if (expirerThread.getState() == Thread.State.NEW) {
expirerThread.start();
}
}
ServerCnxnFactory主要负责socket相关的部分,从start方法可以看出,zk的serverSocket设计为了四种线程,acceptThread来监听accept事件,selectorThread监听读写io,workerPool负责处理IO,expirerThread负责处理过期的连接。
AcceptThread
AcceptThread只处理accept事件,且通过队列进行解耦。
private boolean doAccept() {
boolean accepted = false;
SocketChannel sc = null;
try {
//获取到socketChannel
sc = acceptSocket.accept();
accepted = true;
//中间会校验一下是否达到最大连接
sc.configureBlocking(false);
//建立连接后分配给selector线程,轮询分配
// Round-robin assign this connection to a selector thread
if (!selectorIterator.hasNext()) {
selectorIterator = selectorThreads.iterator();
}
SelectorThread selectorThread = selectorIterator.next();
//将新accept的socket传递给selector
if (!selectorThread.addAcceptedConnection(sc)) {
throw new IOException("Unable to add connection to selector queue"
+ (stopped ? " (shutdown in progress)" : ""));
}
acceptErrorLogger.flush();
}
return accepted;
}
}
public boolean addAcceptedConnection(SocketChannel accepted) {
//将socket放入acceptedQueue,在selectorThread进行处理
if (stopped || !acceptedQueue.offer(accepted)) {
return false;
}
//唤醒阻塞在selectorThread上的select方法
wakeupSelector();
return true;
}
SelectorThread
public void run() {
try {
while (!stopped) {
try {
//处理读写IO事件
select();
//新accept的socket注册read事件
processAcceptedConnections();
//暂时没理解透下面这个方法
processInterestOpsUpdateRequests();
}
}}}
private void select() {
try {
//当收到accept事件或者由wakeupSelector()唤醒selector,下面的循环可能有事件,也可能没有事件,有事件优先处理,没有的话跳出select方法,去给新accept的socket注册read事件
selector.select();
Set<SelectionKey> selected = selector.selectedKeys();
ArrayList<SelectionKey> selectedList = new ArrayList<>(selected);
Collections.shuffle(selectedList);
Iterator<SelectionKey> selectedKeys = selectedList.iterator();
while (!stopped && selectedKeys.hasNext()) {
SelectionKey key = selectedKeys.next();
selected.remove(key);
if (!key.isValid()) {
cleanupSelectionKey(key);
continue;
}
if (key.isReadable() || key.isWritable()) {
//处理IO,其实是将key包装为request扔到workerpool
handleIO(key);
} else {
LOG.warn("Unexpected ops in select {}", key.readyOps());
}
}
}
private void processAcceptedConnections() {
SocketChannel accepted;
while (!stopped && (accepted = acceptedQueue.poll()) != null) {
SelectionKey key = null;
try {
//当前socket注册read事件
key = accepted.register(selector, SelectionKey.OP_READ);
//根据socketChannel创建连接
NIOServerCnxn cnxn = createConnection(accepted, key, this);
//这里key持有了cnxn,这样在处理io的时候才能获取到对应对象
key.attach(cnxn);
addCnxn(cnxn);
} catch (IOException e) {
// register, createConnection
cleanupSelectionKey(key);
fastCloseSock(accepted);
}
}
}
expirerThread
public void run() {
try {
while (!stopped) {
long waitTime = cnxnExpiryQueue.getWaitTime();
if (waitTime > 0) {
Thread.sleep(waitTime);
continue;
}
//关闭过期的链接
for (NIOServerCnxn conn : cnxnExpiryQueue.poll()) {
ServerMetrics.getMetrics().SESSIONLESS_CONNECTIONS_EXPIRED.add(1);
conn.close(ServerCnxn.DisconnectReason.CONNECTION_EXPIRED);
}
}
} catch (InterruptedException e) {
LOG.info("ConnnectionExpirerThread interrupted");
}
}
expirer线程的run逻辑是很简单的,就是从一个队列取出过期的连接,并进行关闭。程序会通过touchCnxn方法,来延长连接的过期时间。touchCnxn方法在创建连接,处理IO事件的前后都会调用。
由于连接和session的过期机制都是一样的,所以这里先不分析cnxnExpiryQueue.poll和cnxnExpiryQueue.update方法,在下面讲到sessionTrack的时候进行分析
public void touchCnxn(NIOServerCnxn cnxn) {
cnxnExpiryQueue.update(cnxn, cnxn.getSessionTimeout());
}
workPool
worker线程的核心任务,是将socket中的数据读取并封装为request,然后交由processor去处理。
void doIO(SelectionKey k) throws InterruptedException {
try {
//前4个字节用来记录长度
if (k.isReadable()) {
//将消息长度写到incomingBuffer,返回值小于0表示没有读到消息长度
int rc = sock.read(incomingBuffer);
if (rc < 0) {
handleFailedRead();
}
//正常来讲,消息长度占4个字节,所以此时limit==position
if (incomingBuffer.remaining() == 0) {
boolean isPayload;
//这里没有特别理解,incomingBuffer什么情况下才会不等于呢??
if (incomingBuffer == lenBuffer) { // start of next request
//变成读模式,会在readLength读到incomingBuffer写入的数据(即长度)
incomingBuffer.flip();
//incomingBuffer在这里会重新分配
isPayload = readLength(k);
incomingBuffer.clear();
} else {
// continuation
isPayload = true;
}
if (isPayload) { // not the case for 4letterword
//读取具体的数据
readPayload();
} else {
// four letter words take care
// need not do anything else
return;
}
}
}
private boolean readLength(SelectionKey k) throws IOException {
// Read the length, now get the buffer
//获取到数据长度
int len = lenBuffer.getInt();
zkServer.checkRequestSizeWhenReceivingMessage(len);
//重新分配长度
incomingBuffer = ByteBuffer.allocate(len);
return true;
}
private void readPayload() throws IOException, InterruptedException, ClientCnxnLimitException {
//刚分配了新的空间,所以这里一定不等于0,因此可以将socket剩余信息写到incomingBuffer
if (incomingBuffer.remaining() != 0) { // have we read length bytes?
int rc = sock.read(incomingBuffer); // sock is non-blocking, so ok
if (rc < 0) {
handleFailedRead();
}
}
//incomingBuffer已经写完数据了,所以下面就是flip后再读数据了
if (incomingBuffer.remaining() == 0) { // have we read length bytes?
incomingBuffer.flip();
packetReceived(4 + incomingBuffer.remaining());
if (!initialized) {
//只在这里面会将initialized设置为true,所以第一次建立连接一定会走进来
readConnectRequest();
} else {
readRequest();
}
lenBuffer.clear();
incomingBuffer = lenBuffer;
}
}
当建立连接后第一次处理io会走到readConnectRequest方法,这个方法封装的是ConnectRequest,由processConnectRequest进行处理
BinaryInputArchive bia = BinaryInputArchive.getArchive(new ByteBufferInputStream(incomingBuffer));
ConnectRequest request = protocolManager.deserializeConnectRequest(bia);
zkServer.processConnectRequest(this, request);
其他时候会走到readRequest,封装的是普通的RequestRecord,由processPacket进行处理
RequestHeader h = new RequestHeader();
ByteBufferInputStream.byteBuffer2Record(incomingBuffer, h);
RequestRecord request = RequestRecord.fromBytes(incomingBuffer.slice());
zkServer.processPacket(this, h, request);
processConnectRequest最核心的工作就是创建了session,并封装了个createSession的request进行处理
if (sessionId == 0) {
long id = createSession(cnxn, passwd, sessionTimeout);
long createSession(ServerCnxn cnxn, byte[] passwd, int timeout) {
if (passwd == null) {
// Possible since it's just deserialized from a packet on the wire.
passwd = new byte[0];
}
long sessionId = sessionTracker.createSession(timeout);
Random r = new Random(sessionId ^ superSecret);
r.nextBytes(passwd);
CreateSessionTxn txn = new CreateSessionTxn(timeout);
cnxn.setSessionId(sessionId);
Request si = new Request(cnxn, sessionId, 0, OpCode.createSession, RequestRecord.fromRecord(txn), null);
submitRequest(si);//所以首次创建session最终还是会走到submitRequest
return sessionId;
}
processPacket的工作则是进行认证校验和request转发
public void processPacket(ServerCnxn cnxn, RequestHeader h, RequestRecord request) throws IOException {
//除了校验之外则是正常的请求转发
if (h.getType() == OpCode.auth) {
...
} else if (h.getType() == OpCode.sasl) {
...
} else {
if (!authHelper.enforceAuthentication(cnxn, h.getXid())) {
// Authentication enforcement is failed
// Already sent response to user about failure and closed the session, lets return
return;
} else {
Request si = new Request(cnxn, cnxn.getSessionId(), h.getXid(), h.getType(), request, cnxn.getAuthInfo());
int length = request.limit();
if (isLargeRequest(length)) {
// checkRequestSize will throw IOException if request is rejected
checkRequestSizeWhenMessageReceived(length);
si.setLargeRequestSize(length);
}
si.setOwner(ServerCnxn.me);
//正常的请求则会从这里进去
submitRequest(si);
}
}
}
至此,我们发现都会走到submitRequest方法,而这个方法的逻辑则是将request扔到节流器
public void submitRequest(Request si) {
if (restoreLatch != null) {
try {
LOG.info("Blocking request submission while restore is in progress");
restoreLatch.await();
} catch (final InterruptedException e) {
LOG.warn("Unexpected interruption", e);
}
}
enqueueRequest(si);//会将request扔到throttler的submittedRequests
}
public void enqueueRequest(Request si) {
if (requestThrottler == null) {
synchronized (this) {
try {
// Since all requests are passed to the request
// processor it should wait for setting up the request
// processor chain. The state will be updated to RUNNING
// after the setup.
while (state == State.INITIAL) {
wait(1000);
}
} catch (InterruptedException e) {
LOG.warn("Unexpected interruption", e);
}
if (requestThrottler == null) {
throw new RuntimeException("Not started");
}
}
}
requestThrottler.submitRequest(si);
}
RequestThrottler
throttler的创建和启动是在startupWithServerState方法中
private void startupWithServerState(State state) {
if (sessionTracker == null) {
createSessionTracker();
}
//用于管理每个链接的session
startSessionTracker();
//以单链表的方式串起来processor
setupRequestProcessors();
//节流器,所有的request都会先过一遍这个
startRequestThrottler();
}
protected void startRequestThrottler() {
requestThrottler = createRequestThrottler();
requestThrottler.start();
}
上面讲到所有的请求都执行了requestThrottler.submitRequest,这个操作实际是将请求放入了submittedRequests队列中,requestThrottler作为一个线程,循环取出队列中的请求并判断是否做限流。
下面的代码主要有两个逻辑:
一是当正在执行的请求数量达到上限时,要一直阻塞到数量小于maxRequests
二是假如请求在队列里等待的时间大于throttled_op_wait_time,标记为已限流,后面的Processor处理时会抛异常。
public void run() {
try {
while (true) {
if (killed) {
break;
}
//从队列取出一个请求
Request request = submittedRequests.take();
if (Request.requestOfDeath == request) {
break;
}
if (request.mustDrop()) {
continue;
}
// Throttling is disabled when maxRequests = 0
if (maxRequests > 0) {
while (!killed) {
//一直都没有处理,导致连接都关闭了,或者session超时了,丢掉请求
if (dropStaleRequests && request.isStale()) {
// Note: this will close the connection
dropRequest(request);
ServerMetrics.getMetrics().STALE_REQUESTS_DROPPED.add(1);
request = null;
break;
}
//没达到上限时跳出循环
if (zks.getInProcess() < maxRequests) {
break;
}
//达到上限了的话,等待stallTime这么在重新进循环,避免过多执行循环
throttleSleep(stallTime);
}
}
if (killed) {
break;
}
// A dropped stale request will be null
if (request != null) {
if (request.isStale()) {
ServerMetrics.getMetrics().STALE_REQUESTS.add(1);
}
final long elapsedTime = Time.currentElapsedTime() - request.requestThrottleQueueTime;
ServerMetrics.getMetrics().REQUEST_THROTTLE_QUEUE_TIME.add(elapsedTime);
//当在队列等待时间过长,大于限流等待时间时,会将请求标志位已限流;已限流的请求在finalRequestProcessor中会抛异常Code.THROTTLEDOP
if (shouldThrottleOp(request, elapsedTime)) {
request.setIsThrottled(true);
ServerMetrics.getMetrics().THROTTLED_OPS.add(1);
}
//交由Processor去处理
zks.submitRequestNow(request);
}
}
}
假如没有被限流的话,执行到zks.submitRequestNow(request);后就将request交给processor处理了
RequestProcessor
zookeeper中将Processor分为了三个Processor,其启动是在setupRequestProcessors方法中,以链表的形式串起了三个processor,以PrepRequestProcessor为head,FinalRequestProcessor为tail。
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this, finalProcessor);
((SyncRequestProcessor) syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor) firstProcessor).start();
}
public PrepRequestProcessor(ZooKeeperServer zks, RequestProcessor nextProcessor) {
this.nextProcessor = nextProcessor;
public SyncRequestProcessor(ZooKeeperServer zks, RequestProcessor nextProcessor) {
this.zks = zks;
this.nextProcessor = nextProcessor;
PrepRequestProcessor
PrepRequestProcessor的主要工作就是校验和创建事务。
当调用processRequest时,也是通过队列解耦了一下,通过线程去异步执行,核心方法就是pRequestHelper
public void processRequest(Request request) {
request.prepQueueStartTime = Time.currentElapsedTime();
submittedRequests.add(request);
ServerMetrics.getMetrics().PREP_PROCESSOR_QUEUED.add(1);
}
public void run() {
LOG.info(String.format("PrepRequestProcessor (sid:%d) started, reconfigEnabled=%s", zks.getServerId(), zks.reconfigEnabled));
try {
while (true) {
Request request = submittedRequests.take();
...不重要的逻辑
pRequest(request);
}
}
protected void pRequest(Request request) throws RequestProcessorException {
request.setHdr(null);
request.setTxn(null);
//正常情况下request的isThrottled应该是false,所以会执行pRequestHelper
if (!request.isThrottled()) {
//一些前置的校验,事务的创建等
pRequestHelper(request);
}
//获取事务ID,
request.zxid = zks.getZxid();
long timeFinishedPrepare = Time.currentElapsedTime();
ServerMetrics.getMetrics().PREP_PROCESS_TIME.add(timeFinishedPrepare - request.prepStartTime);
//由syncRequestProcessor执行
nextProcessor.processRequest(request);
ServerMetrics.getMetrics().PROPOSAL_PROCESS_TIME.add(Time.currentElapsedTime() - timeFinishedPrepare);
}
pRequestHelper方法里根据不同的OpCode有各自的处理方法,但是总共依旧可以区分为两大类:需要创建事务和不需要创建事务
不需要创建事务的如下,就只执行checkSession方法,就是校验一下session是否正常

而需要创建事务的逻辑则也差不多,大多数都是封装为一个Request对象,然后执行pRequest2Txn方法

pRequest2Txn方法的主要逻辑则是校验request、校验Acl权限、校验路径、校验[quota](Zookeeper笔记之quota - CC11001100 - 博客园)、创建事务和创建事务摘要
//校验request
validateCreateRequest(path, createMode, request, ttl);
//acl权限校验
zks.checkACL(request.cnxn, parentRecord.acl, ZooDefs.Perms.CREATE, request.authInfo, path, listACL);
//校验路径名称合规
validatePath(path, request.sessionId);
//校验节点数和字节数
zks.checkQuota(path, null, data, OpCode.create);
//创建事务
request.setTxn(new CreateTxn(path, data, listACL, createMode.isEphemeral(), newCversion));
//事务摘要
setTxnDigest(request, nodeRecord.precalculatedDigest);
SyncRequestProcessor
SyncRequestProcessor主要有两个操作,一个是写事务,一个是生成快照。
对于非事务操作,这个processor是没有意义的;只有事务操作,才会进行日志的持久化。
public void run() {
try {
// we do this in an attempt to ensure that not all of the servers
// in the ensemble take a snapshot at the same time
resetSnapshotStats();
lastFlushTime = Time.currentElapsedTime();
while (true) {
ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUE_SIZE.add(queuedRequests.size());
long pollTime = Math.min(zks.getMaxWriteQueuePollTime(), getRemainingDelay());
//之所有先poll一次是为了当queuedRequests队列为null的时候,期望可以触发一下flush
Request si = queuedRequests.poll(pollTime, TimeUnit.MILLISECONDS);
if (si == null) {
/* We timed out looking for more writes to batch, go ahead and flush immediately */
flush();
si = queuedRequests.take();
}
if (si == REQUEST_OF_DEATH) {
break;
}
long startProcessTime = Time.currentElapsedTime();
ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUE_TIME.add(startProcessTime - si.syncQueueStartTime);
// 普通的查询都没有事务,所以都会返回false;append这里只是写到了流里,还需要在commit方法中调用flush才会落盘
if (!si.isThrottled() && zks.getZKDatabase().append(si)) {
if (shouldSnapshot()) {
resetSnapshotStats();
// roll the log
zks.getZKDatabase().rollLog();
// take a snapshot
if (!snapThreadMutex.tryAcquire()) {
LOG.warn("Too busy to snap, skipping");
} else {
new ZooKeeperThread("Snapshot Thread") {
public void run() {
try {
zks.takeSnapshot();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
snapThreadMutex.release();
}
}
}.start();
}
}
} else if (toFlush.isEmpty()) {
// optimization for read heavy workloads
// iff this is a read or a throttled request(which doesn't need to be written to the disk),
// and there are no pending flushes (writes), then just pass this to the next processor
//当没有需要flush的内容,直接调用下一个processor处理;但假如toFlush队列有内容,就只能排队处理了
if (nextProcessor != null) {
nextProcessor.processRequest(si);
if (nextProcessor instanceof Flushable) {
((Flushable) nextProcessor).flush();
}
}
continue;
}
//排队处理
toFlush.add(si);
if (shouldFlush()) {
flush();
}
ServerMetrics.getMetrics().SYNC_PROCESS_TIME.add(Time.currentElapsedTime() - startProcessTime);
}
} catch (Throwable t) {
handleException(this.getName(), t);
}
LOG.info("SyncRequestProcessor exited!");
}
关于写事务的方法是append和flush
public synchronized boolean append(Request request) throws IOException {
TxnHeader hdr = request.getHdr();
//普通的查询都没有事务,所以都会返回false
if (hdr == null) {
return false;
}
...
//当logStream == null时会新创建文件,首次创建或者文件达到上限新创建
if (logStream == null) {
LOG.info("Creating new log file: {}", Util.makeLogName(hdr.getZxid()));
logFileWrite = new File(logDir, Util.makeLogName(hdr.getZxid()));
fos = new FileOutputStream(logFileWrite);
logStream = new BufferedOutputStream(fos);
oa = BinaryOutputArchive.getArchive(logStream);
FileHeader fhdr = new FileHeader(TXNLOG_MAGIC, VERSION, dbId);
long dataSize = oa.getDataSize();
fhdr.serialize(oa, "fileheader");
// Make sure that the magic number is written before padding.
//新建文件的文件头要立刻flush
logStream.flush();
filePosition += oa.getDataSize() - dataSize;
filePadding.setCurrentSize(filePosition);
//在commit的时候进行flush
streamsToFlush.add(fos);
}
fileSize = filePadding.padFile(fos.getChannel(), filePosition);
//request序列化
byte[] buf = request.getSerializeData();
if (buf == null || buf.length == 0) {
throw new IOException("Faulty serialization for header " + "and txn");
}
long dataSize = oa.getDataSize();
Checksum crc = makeChecksumAlgorithm();
crc.update(buf, 0, buf.length);
oa.writeLong(crc.getValue(), "txnEntryCRC");
//将request写到流里
Util.writeTxnBytes(oa, buf);
unFlushedSize += oa.getDataSize() - dataSize;
return true;
}
private void flush() throws IOException, RequestProcessorException {
if (this.toFlush.isEmpty()) {
return;
}
ServerMetrics.getMetrics().BATCH_SIZE.add(toFlush.size());
long flushStartTime = Time.currentElapsedTime();
//将事务日志从流里刷到盘里
zks.getZKDatabase().commit();
ServerMetrics.getMetrics().SYNC_PROCESSOR_FLUSH_TIME.add(Time.currentElapsedTime() - flushStartTime);
if (this.nextProcessor == null) {
this.toFlush.clear();
} else {
while (!this.toFlush.isEmpty()) {
final Request i = this.toFlush.remove();
long latency = Time.currentElapsedTime() - i.syncQueueStartTime;
ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUE_AND_FLUSH_TIME.add(latency);
//到finalRequestProcessor
this.nextProcessor.processRequest(i);
}
if (this.nextProcessor instanceof Flushable) {
((Flushable) this.nextProcessor).flush();
}
}
lastFlushTime = Time.currentElapsedTime();
}
public synchronized void commit() throws IOException {
if (logStream != null) {
logStream.flush();
filePosition += unFlushedSize;
// If we have written more than we have previously preallocated,
// we should override the fileSize by filePosition.
if (filePosition > fileSize) {
fileSize = filePosition;
}
unFlushedSize = 0;
}
for (FileOutputStream log : streamsToFlush) {
//刷盘
log.flush();
...
}
while (streamsToFlush.size() > 1) {
streamsToFlush.poll().close();
}
// 达到上限了创建新事务文件
if (txnLogSizeLimit > 0) {
long logSize = getCurrentLogSize();
if (logSize > txnLogSizeLimit) {
LOG.debug("Log size limit reached: {}", logSize);
//创建新文件
rollLog();
}
}
}
FinalRequestProcessor
到目前为止,如果是查询请求,那还没有进行查询操作;如果是事务请求,只是将事务落盘了,内存中还没有进行修改。加上返回对象的组装,这些都是在这个Processor进行处理的。下面分别以创建节点和查询数据两个为例
创建节点(create)
创建节点属于事务操作,所以在返回结果之间要同步修改内存中的值,核心方法是applyRequest,一直会执行到DataTree的processTxn
public void processRequest(Request request) { LOG.debug("Processing request:: {}", request); ProcessTxnResult rc = null; if (!request.isThrottled()) { //处理事务或session rc = applyRequest(request); }

将其执行结果封装为response,并发送出去


查询数据(getData)
由于查询数据不是事务,所以在applyRequest中并没有啥操作,直接走到下面的switch,封装request,然后从zkDataBase获取节点,再获取数据封装为response并返回



SessionTracker
session是逻辑上客户端和服务端的一次长连接的通话,依托于物理的长连接connection。当第一次建立连接之后,zookeeper会为这个链接创建一个session并设置一个过期时间,只要没到过期时间,期间哪怕连接断开,只要可以重新连接,那依然算作一个session内。
zookeeper利用session实现了如临时节点,即当session过期,当前session所建立的临时节点都会被删除。
sessionTrack的创建也是在zookeeperServer.start的时候
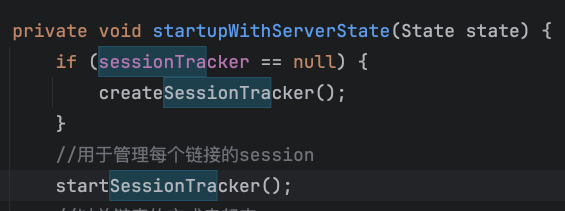

而session的过期处理和connect的过期处理逻辑基本一样,在这里以session讲解一下逻辑,上面的connect过期部分也就看的懂了。
public void run() {
try {
while (running) {
long waitTime = sessionExpiryQueue.getWaitTime();
if (waitTime > 0) {
Thread.sleep(waitTime);
continue;
}
//看似是poll,其实是取出expiryMap中已经过期的队列
for (SessionImpl s : sessionExpiryQueue.poll()) {
ServerMetrics.getMetrics().STALE_SESSIONS_EXPIRED.add(1);
setSessionClosing(s.sessionId);
expirer.expire(s);//其实就是close操作
}
}
}
}
过期逻辑核心是一个队列ExpiryQueue,核心方法是update和poll方法。
ExpiryQueue持有两个集合对象elemMap和expiryMap,
elemMap的key为连接对象,在这里就是指session,在connect逻辑中就是指connect,value是其过期时间。
expiryMap的key是过期时间,value是当前过期时间下对应的连接的集合。结构大概如下图。

此外,ExpiryQueue还记录了下一个要过期的时间nextExpirationTime,因此,对于poll方法,就是遍历expiryMap,找到nextExpirationTime<now<key的values,并关闭即可
public Set<E> poll() {
long now = Time.currentElapsedTime();
//当前最后一个要过期的时间
long expirationTime = nextExpirationTime.get();
//时间还没到,所以都不过期
if (now < expirationTime) {
return Collections.emptySet();
}
Set<E> set = null;
//计算下一个周期并赋值
long newExpirationTime = expirationTime + expirationInterval;
if (nextExpirationTime.compareAndSet(expirationTime, newExpirationTime)) {
//取到上一个过期的周期的集合
set = expiryMap.remove(expirationTime);
}
if (set == null) {
return Collections.emptySet();
}
return set;
}
而update方法也好理解,其实就是给session续期,假如续期之后其落到下个周期了,则要从上个周期对应的集合移除,添加到下个周期的集合
public Long update(E elem, int timeout) {
//取到session的之前过期时间
Long prevExpiryTime = elemMap.get(elem);
long now = Time.currentElapsedTime();
//续期
Long newExpiryTime = roundToNextInterval(now + timeout);
//续期之后依然属于上个周期,则不需要改变expiryMap
if (newExpiryTime.equals(prevExpiryTime)) {
// No change, so nothing to update
return null;
}
//续期之后不属于上个周期了,则要将当前sessoin加到下一个周期的集合,并从上一个集合删除
// First add the elem to the new expiry time bucket in expiryMap.
Set<E> set = expiryMap.get(newExpiryTime);
if (set == null) {
// Construct a ConcurrentHashSet using a ConcurrentHashMap
set = Collections.newSetFromMap(new ConcurrentHashMap<>());
// Put the new set in the map, but only if another thread
// hasn't beaten us to it
Set<E> existingSet = expiryMap.putIfAbsent(newExpiryTime, set);
if (existingSet != null) {
set = existingSet;
}
}
set.add(elem);
// Map the elem to the new expiry time. If a different previous
// mapping was present, clean up the previous expiry bucket.
prevExpiryTime = elemMap.put(elem, newExpiryTime);
if (prevExpiryTime != null && !newExpiryTime.equals(prevExpiryTime)) {
Set<E> prevSet = expiryMap.get(prevExpiryTime);
if (prevSet != null) {
prevSet.remove(elem);
}
}
return newExpiryTime;
}
而update方法的调用上层是touchSession,在Processor处理前会调用。
参考文档:
【图解源码】Zookeeper3.7源码分析,包含服务启动流程源码、网络通信源码、RequestProcessor处理请求源码 - 掘金
【图解源码】Zookeeper3.7源码剖析,Session的管理机制,Leader选举投票规则,集群数据同步流程 - 掘金